How MoE Models Reason in Southeast Asian Languages
Decoding the “Translationese” Shadow: How MoE Models Reason in Southeast Asian Languages
If you’ve been following the recent explosion of Large Language Models (LLMs), you’ve likely heard of the Mixture-of-Experts (MoE) architecture. Models like Mixtral or Alibaba’s Qwen3 use this architecture to stay computationally efficient while scaling to trillions of parameters. However, does this “efficiency” hold up for our regional Southeast Asian (SEA) languages, or are we just living in the shadow of English-centric routing?
For my final NLP project at SUTD, I took a deep dive into the qualitative mechanics of how MoE models, specifically Qwen3-30B-A3B, navigate the linguistic landscape of SEA languages like Indonesian, Thai, and Vietnamese.
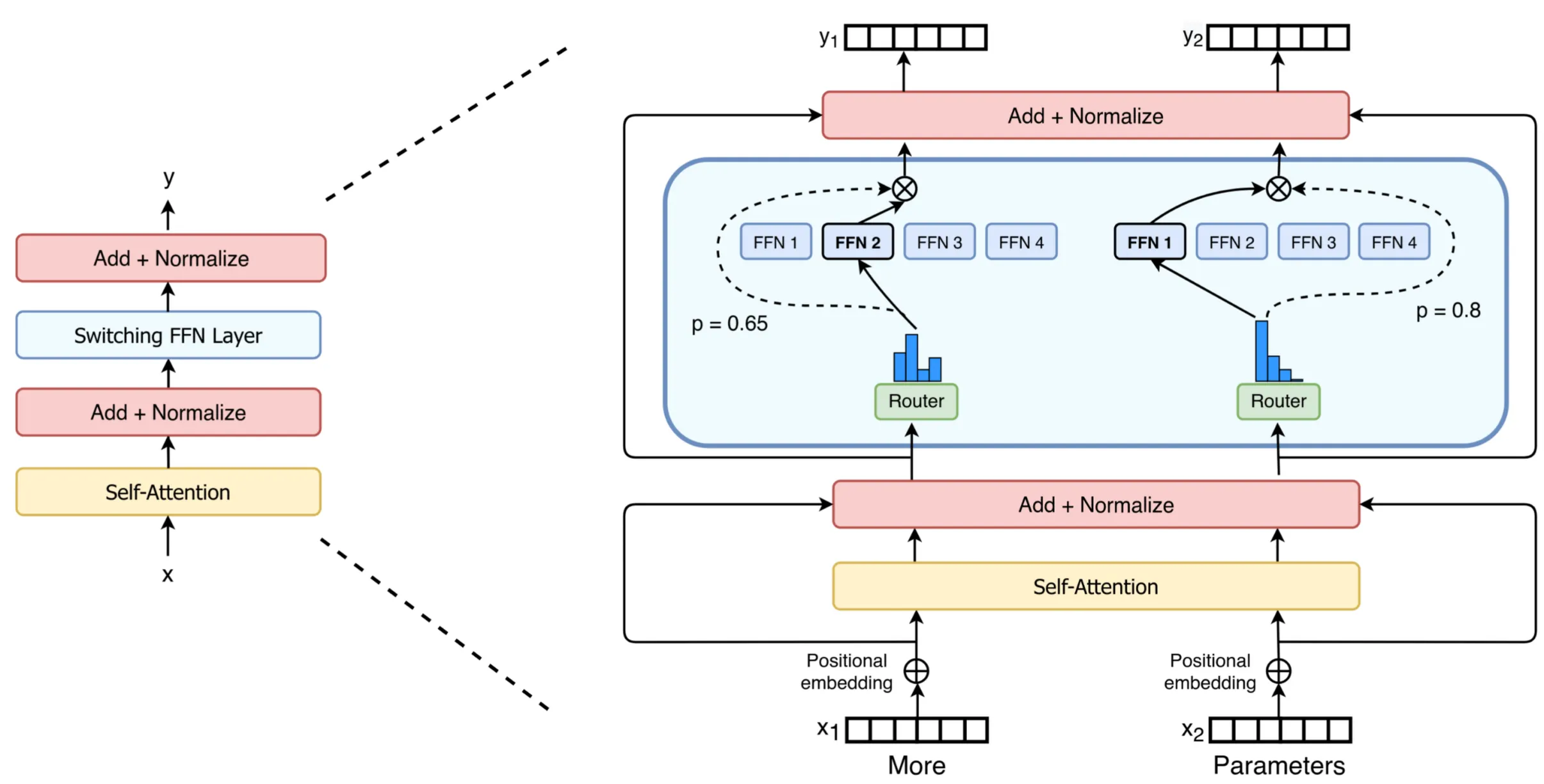
The Semantic Hub Hypothesis
The prevailing theory in dense models is the “Semantic Hub Hypothesis”. It suggests that models project different languages into a unified “universal” representation space in their middle layers—effectively a “language of thought” that is usually dominated by English.
Recent literature by Bandarkar et al. (2025) suggests that MoE models follow a U-shaped divergence curve:
- Early Layers: Specialize in language-specific tokens (high divergence).
- Middle Layers: Share experts across languages to form a “universal hub” (low divergence).
- Late Layers: Diverge again to specialize in the target output language.
This research project sought to test if this hub is truly “universal” or if it’s biased toward Western-centric concepts.
The “W-Shape” and the Translationese Effect
By analyzing routing weights on the SeaExam dataset (regional educational questions), I discovered something the standard benchmarks missed.
The “W-Shape” Phenomenon
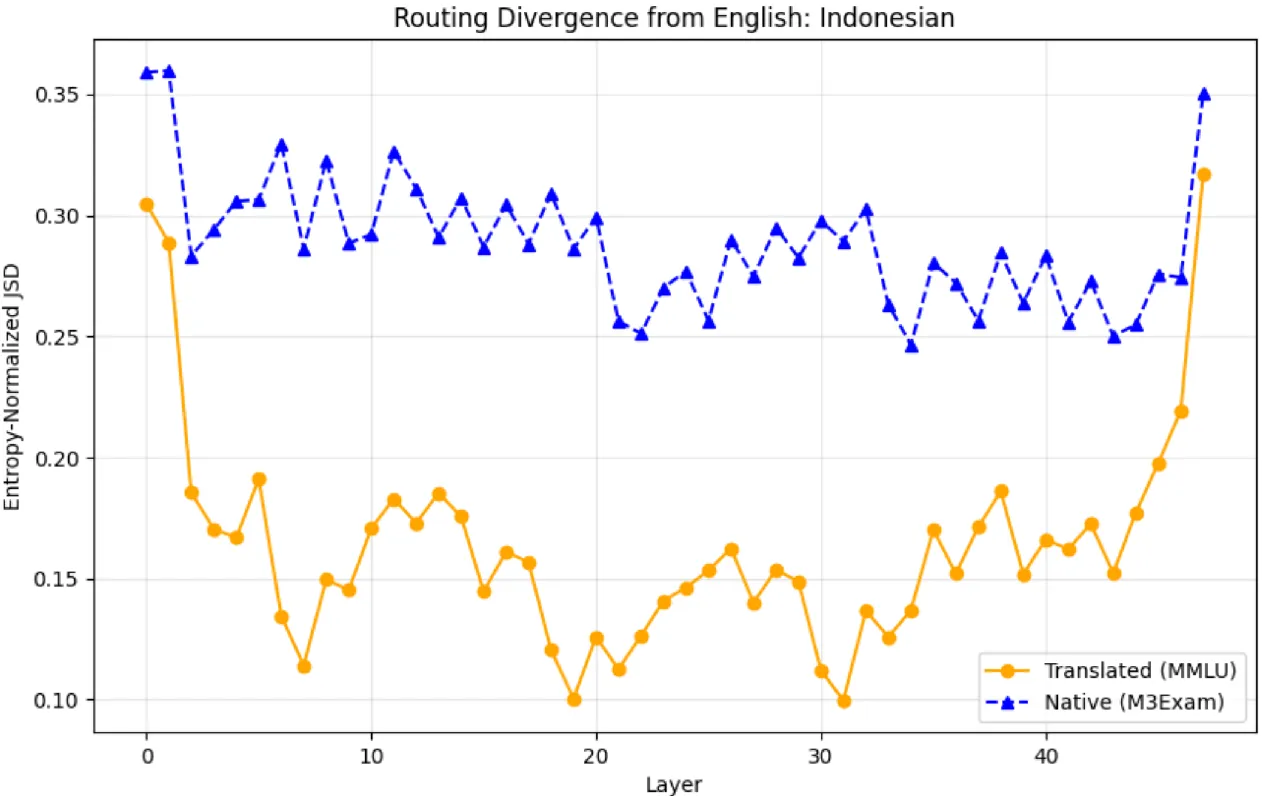
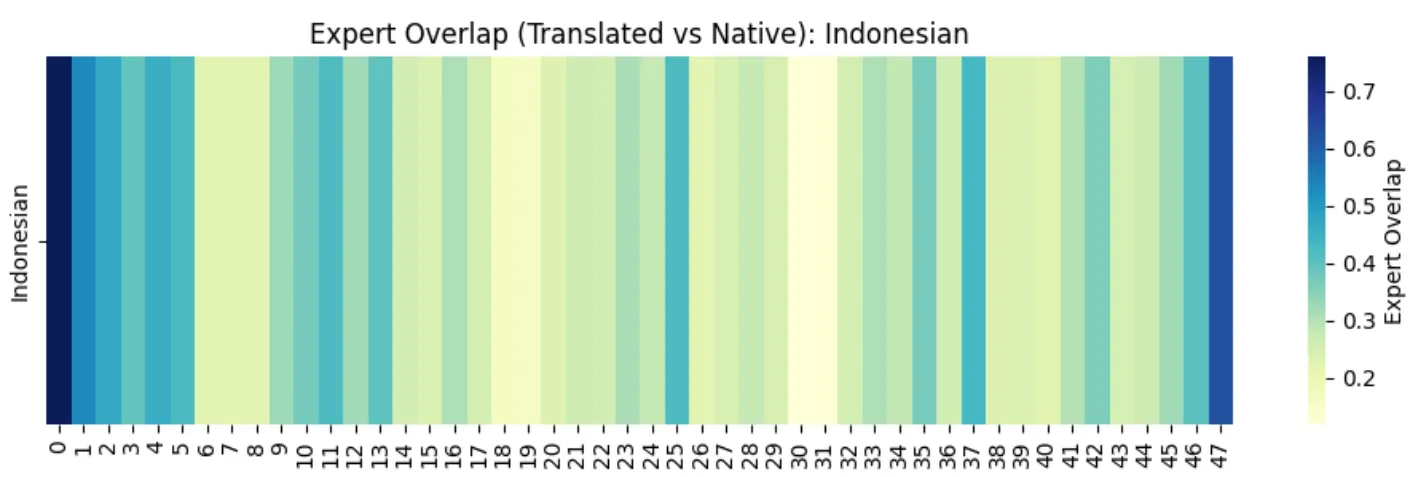
While general text follows the classic U-shape, complex native reasoning in Thai and Vietnamese introduces “kinks” or a “W-shape” in the middle layers (layers 13, 25, 38).
- When the model encounters truly native, culturally-grounded reasoning tasks, it bypasses the “universal” shared experts. It seems to search for language-specific experts that weren’t heavily aligned toward English during instruction tuning.
Visualizing “Translationese”
Here I used t-SNE to project the router space of Layer 24 into 2D. The results were very interesting:
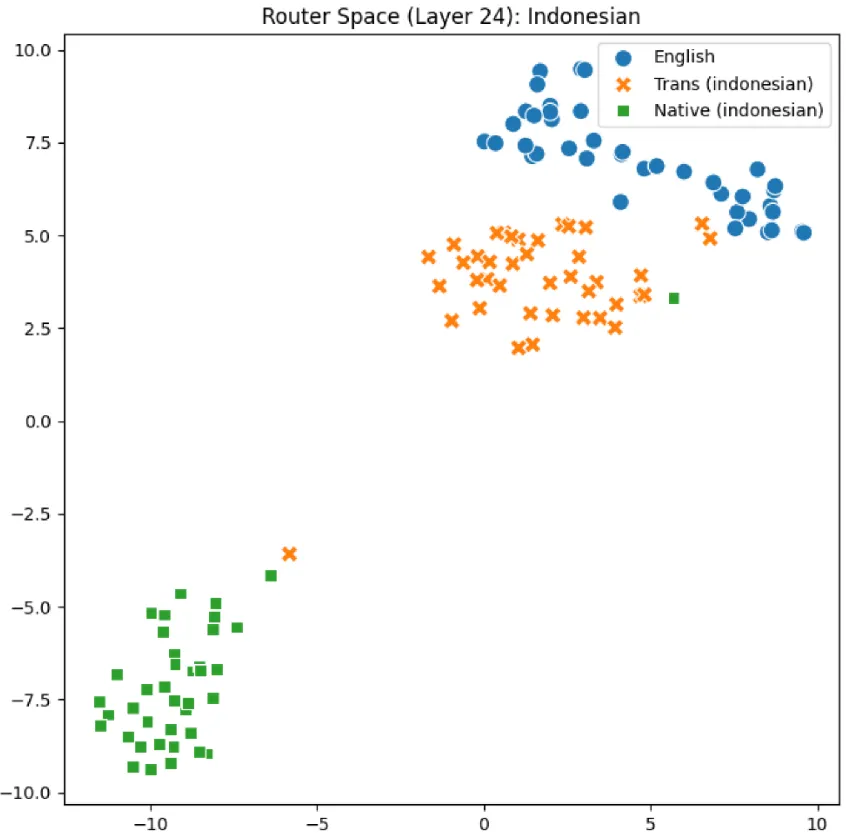
- Clustering: Translated Indonesian (from English MMLU) clustered almost perfectly with English.
- The Gap: Native Indonesian (M3Exam) sat in a completely different representational space.
- The Conclusion: The router doesn’t just see “Indonesian”; it sees the syntactic shadow of English in translated text. This “Translationese” effect means that translated benchmarks may not be measuring a model’s true regional capability at all.
What’s Next? Steering the Native Reasoner
These findings suggest that our current “universal” models might be culture-sensitive but translation-agnostic. The middle layers where the “reasoning engine” is located, is where the real divergence happens.
Moving forward, I’m interested in Model Steering. If we can identify which experts are “Native Experts,” could we force-activate them when a user asks a question in Vietnamese or Thai? This could potentially bridge the performance gap between native and translated content without the need for massive retraining.
Note: Check out the github link for the paper and code!
← Back to projects